Oh no, Elon Musk accidentally revealed the parameters of Claude models?
In short: Sonnet 1T, Opus 5T.
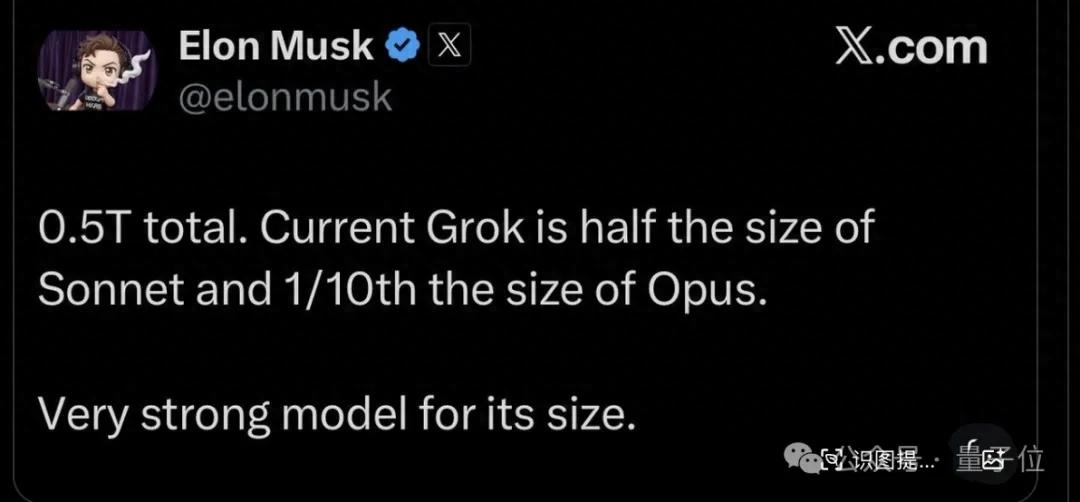
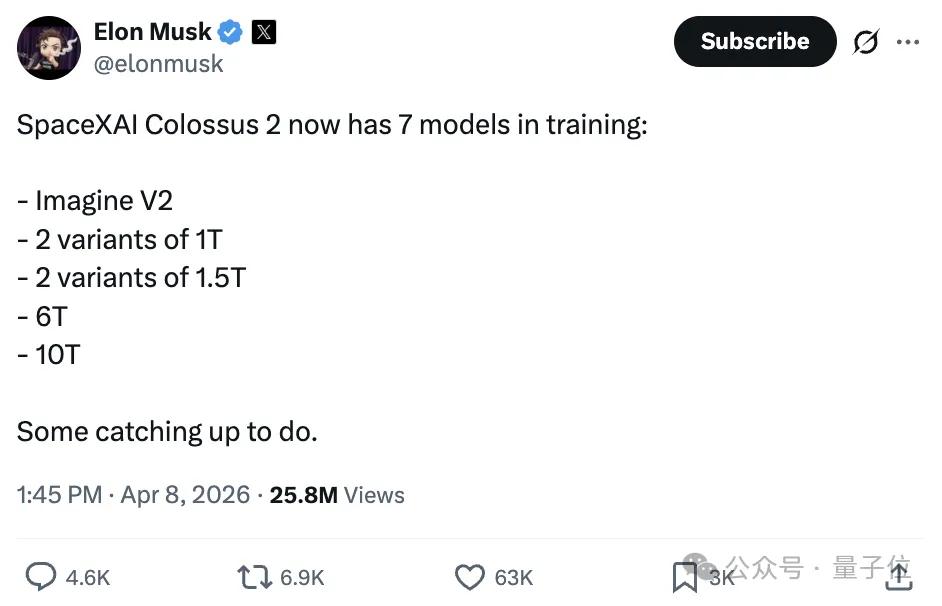
The incident began when Musk posted that xAI’s Colossus 2 supercomputer is training seven models, with the largest model reaching 10 trillion parameters.
Complete list:
- Imagine V2
- 2 models with 1 trillion (1T) parameters each
- 2 models with 1.5 trillion (1.5T) parameters each
- 6 trillion (6T) parameter model
- 10 trillion (10T) parameter model
P.S. Colossus 2 is part of Musk’s Macrohard plan. As of August 2025, Colossus 2 has installed 119 air-cooled chillers providing about 200MW of cooling capacity, sufficient to support approximately 110,000 GB200 NVL72 GPUs.
According to the plan, the first phase of Colossus 2 will deploy 110,000 NVIDIA GB200 GPUs, with a final goal of over 550,000 GPUs and a peak power demand expected to exceed 1.1GW.
This tweet was one of the few times Musk publicly shared specific training plans for the Colossus supercomputer.
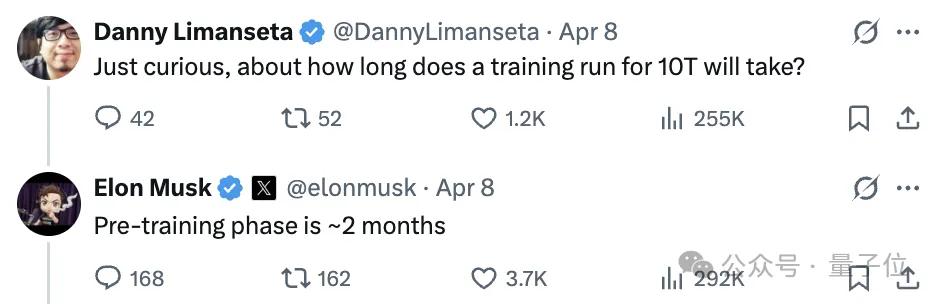
As the news broke, netizens became curious, and Musk appeared to be in a good mood, responding to numerous questions.
For instance, when asked, “How long does it take to train a 10T model?”, Musk replied that the pre-training phase would take about 2 months.
A conversation ensued:
The parameter count of Grok 4.2 is only 5% of xAI’s largest model currently in training. That is, 500 billion (500B) compared to 10 trillion (10T), with the latter being 20 times the former.
Is Grok 4.2 really a total parameter count of 500B, or is it just the activated parameter count within a larger MoE?
In response to the query, Musk stated:
The total parameter count is indeed 0.5T (500 billion). Currently, Grok has half the parameters of Sonnet and one-tenth of Opus. Given its scale, it is a very powerful model.
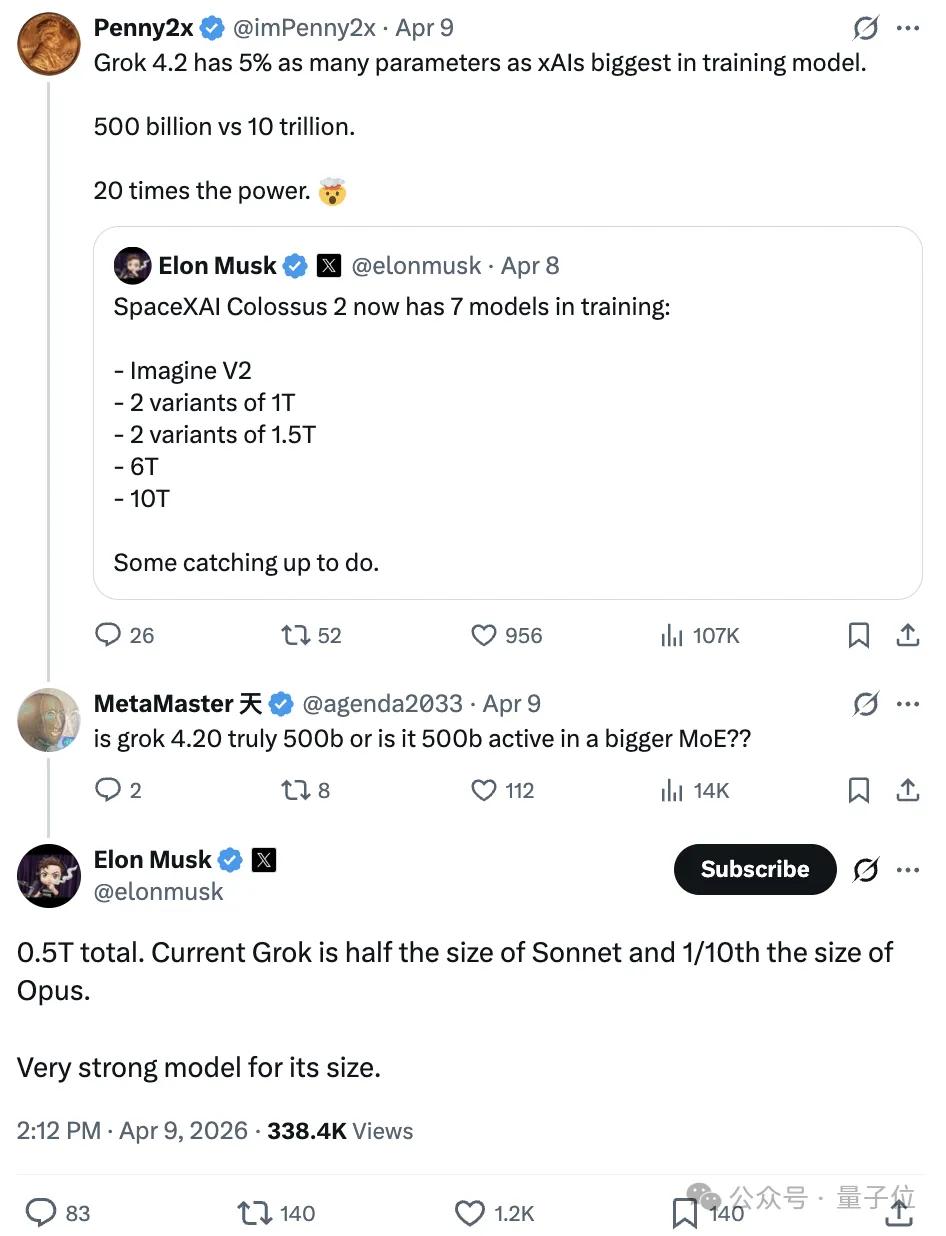
Netizens quickly pointed out the implication that Sonnet is 1T and Opus is 5T.
Someone asked:
Out of pure curiosity, how do you (Musk) know the sizes of Sonnet and Opus?

Musk did not respond, but the point raised by netizens was reasonable: “Top talents move between these few companies, so there seems to be no secret that can be hidden for long.”
Claude Model Parameters Speculated by Netizens
Since the Claude series models were released, Anthropic has kept the parameter sizes strictly confidential, whether for Opus or Sonnet, revealing nothing.
The less they say, the more discussions netizens have.
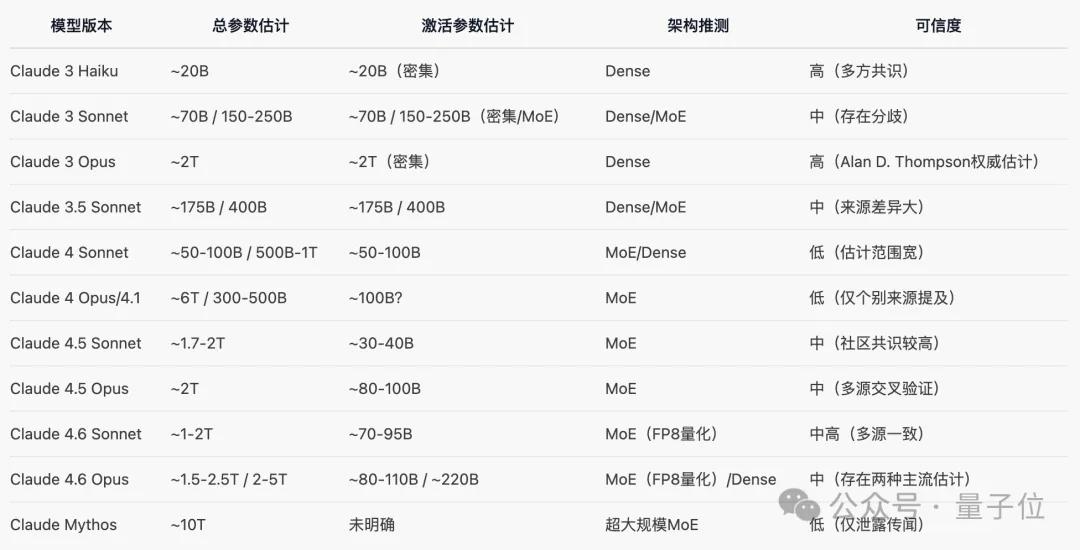
We summarized different speculations about Claude’s parameter sizes from AI analyses based on netizen discussions.
Interestingly, the latest model Claude 4.6 Sonnet is speculated to be around 1-2T, and Claude 4.6 Opus around 1.5-2.5T/2-5T, which aligns with Musk’s accidental leak of “Sonnet 1T, Opus 5T.”
Here are the main speculation methods:
- Inference Cost and Throughput Back Calculation: The model inference cost is approximately linearly related to the activated parameter count, while the total parameter count can be estimated based on architecture type and industry experience coefficients.
- Performance Benchmark Comparison: By comparing performance with known parameter open-source models on standardized benchmarks, the parameter size of closed-source models can be inferred.
- Internal Document Leaks and Rumor Analysis: Information accidentally exposed by officials & some rumors.
- Architecture Feature Analysis: Observing model behavior characteristics to infer the architecture type and narrow down parameter estimates.
First, let’s look at the Claude 3 series, released in March 2024, which formed a clear product matrix with three differently positioned versions.
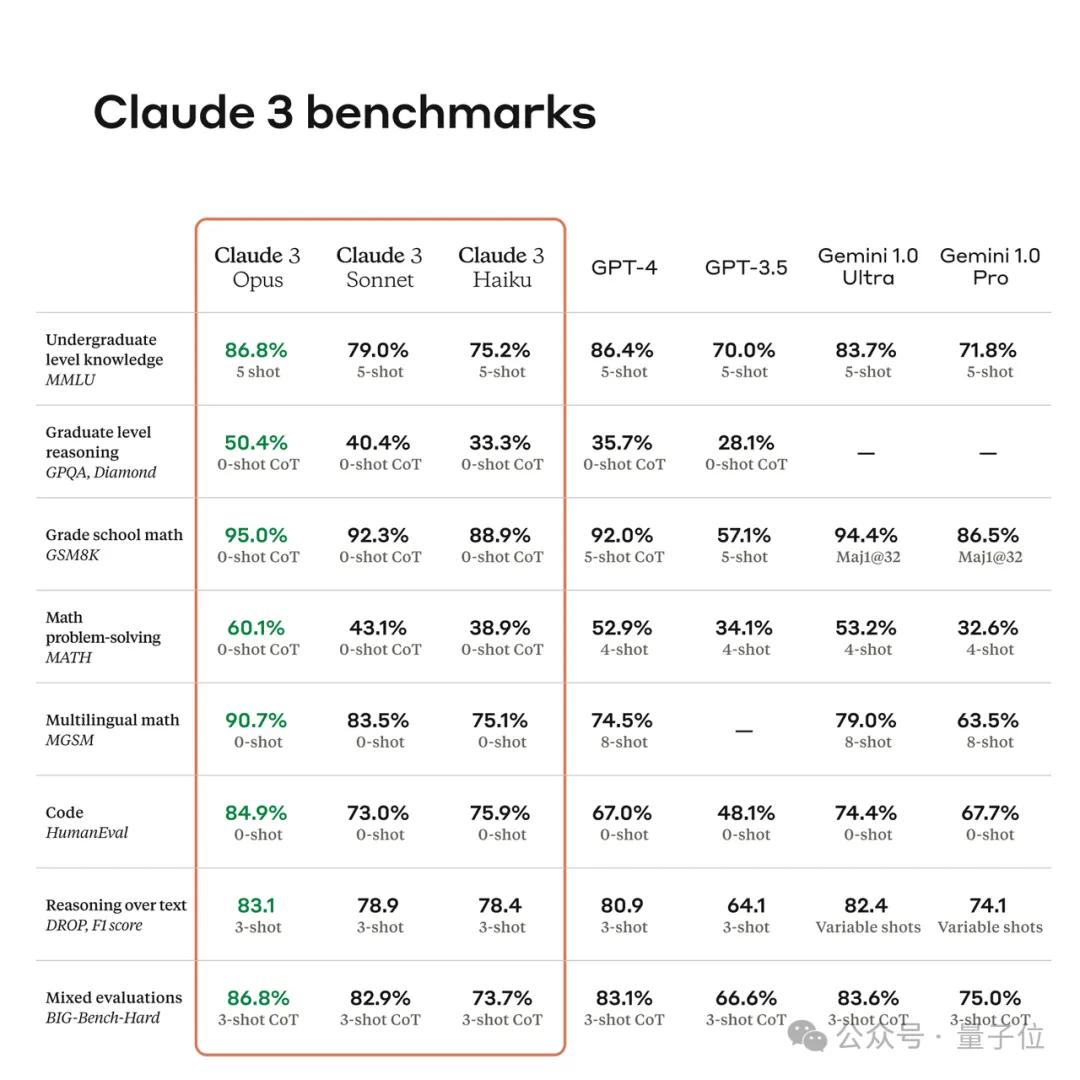
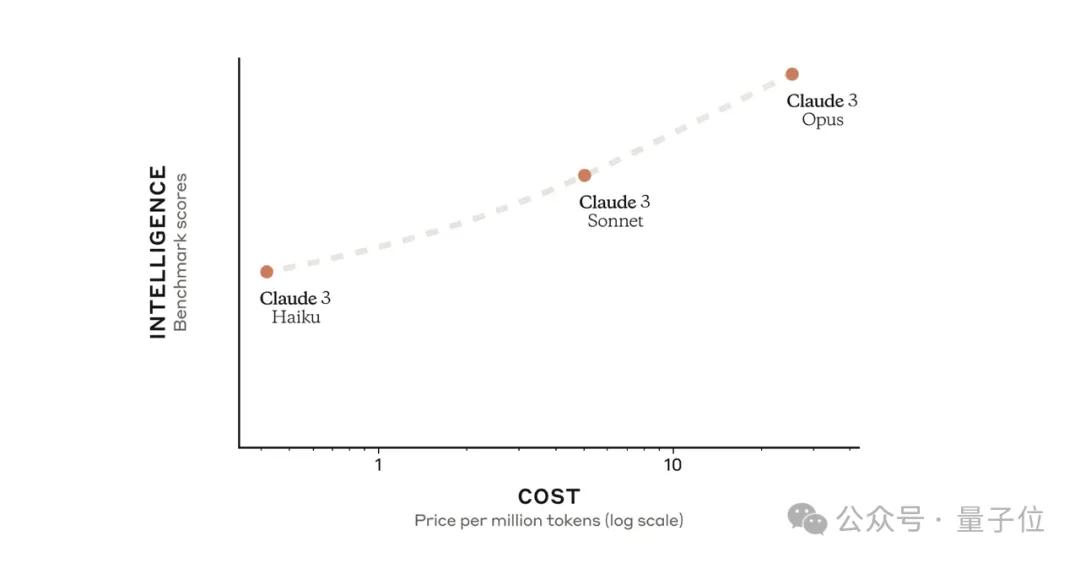
Small cup Haiku, medium cup Sonnet, and large cup Opus, with costs and performance increasing accordingly.
Regarding their parameter sizes, Alan D. Thompson, founder of LifeArchitect.ai, provided estimates:
- Claude 3 Haiku (~20B)
- Claude 3 Sonnet (~70B)
- Claude 3 Opus (~2T)

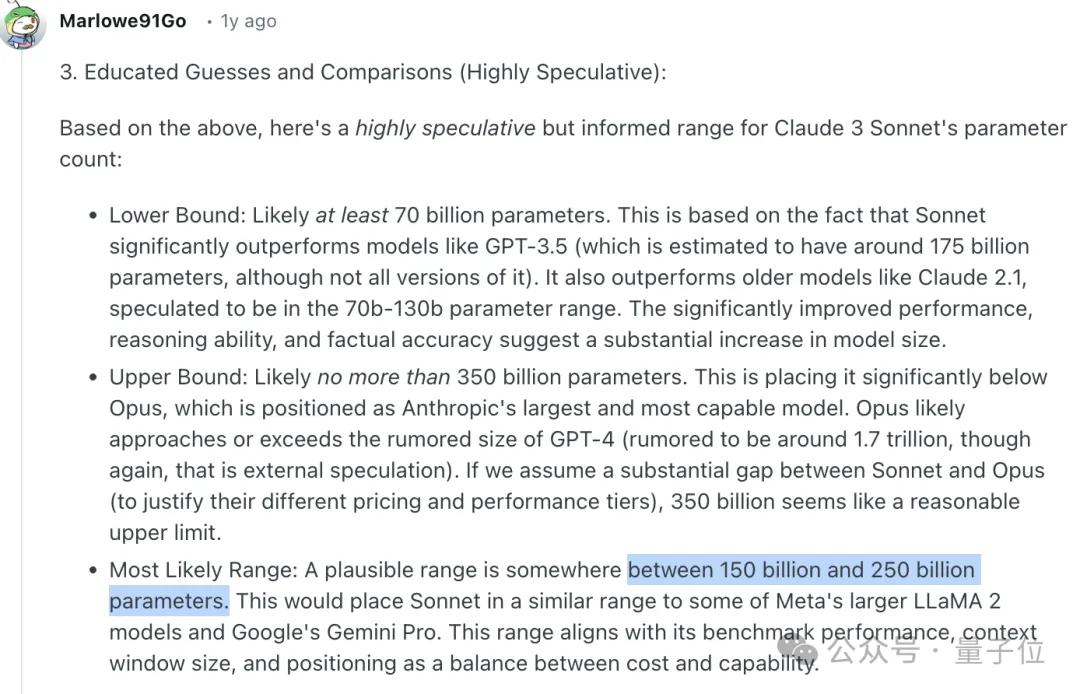
For Claude 3 Sonnet, Reddit community discussions suggested that the parameter count might range between 150-250B based on performance.
Next is Claude 3.5, a significant upgrade that outperformed GPT-4 in several key metrics.
However, Anthropic initially only released Claude 3.5 Sonnet.
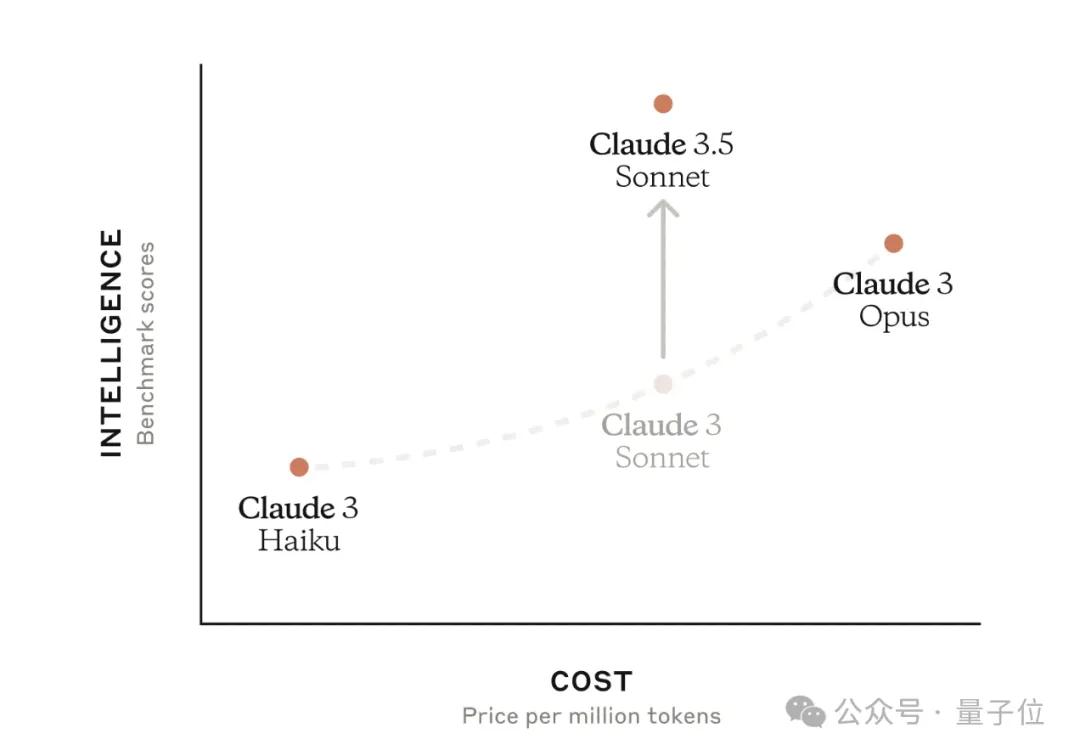
Its speed is twice that of Claude 3 Opus, but its cost is only one-fifth of the latter.
Regarding model parameters, Microsoft and others published a paper stating that, according to industry estimates, Claude 3.5 Sonnet has about 175B parameters.
Other model parameter estimates include: ChatGPT ~175B, GPT-4 ~1.76T, GPT-4o ~200B, o1-mini ~100B, o1-preview ~300B.

Later, Anthropic skipped the 3.5 naming and did not release 3.5 Opus, moving directly to the 4 series with two models:
Claude Opus 4 and Claude Sonnet 4.
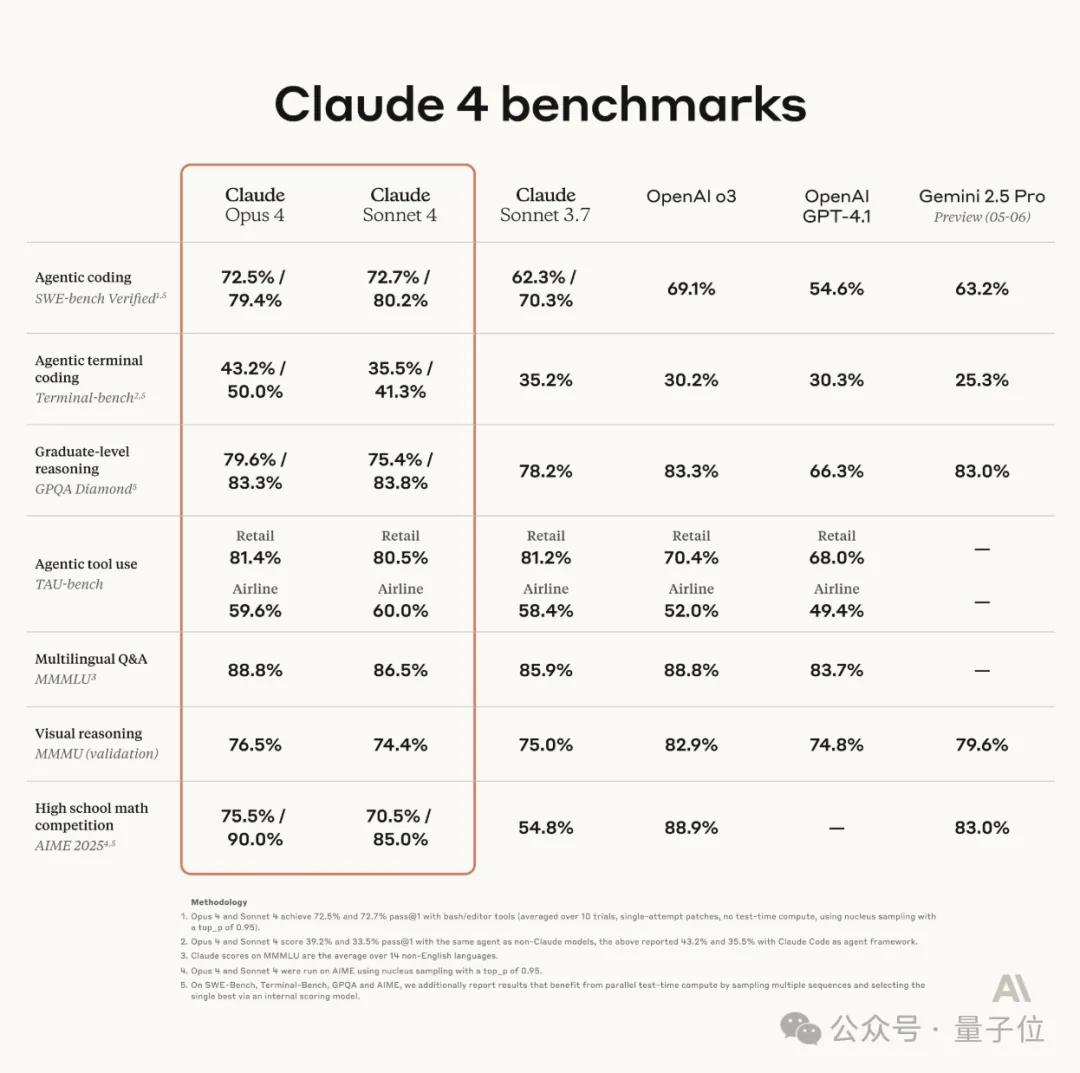
There is considerable disagreement in the industry regarding the parameter estimates for Claude 4.
Industry estimates suggest Claude Opus 4 has around 300–500B parameters, while Claude Sonnet 4 is estimated to have between 50B-100B.
Next came Claude Opus 4.1, which achieved breakthroughs in programming performance, surpassing Claude Opus 4 and further upgrading in Agent tasks and reasoning.
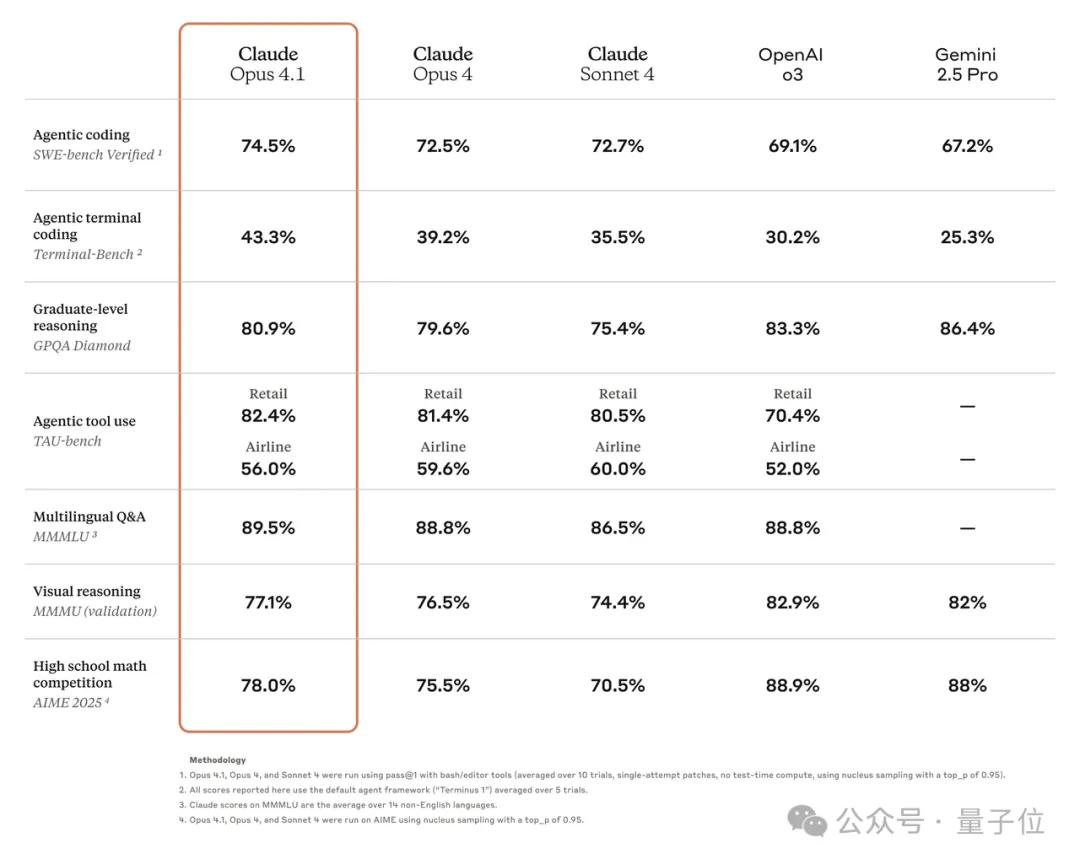
However, the official announcement indicated plans for larger upgrades and improvements in the coming weeks, suggesting that 4.1 is merely a minor update replacing Opus 4.
Some netizens speculated that Anthropic might not have intended to release the model but did so to maintain market competitiveness due to the influx of news about GPT-5/Gemini-3, which might explain the lack of parameter discussions.
A user on Hacker News suggested that it could be an experimental product with a super-large parameter scale, while the subsequent 4.5 version reduced the parameter scale to optimize efficiency.
Anthropic distilled Opus 4/4.1 to obtain Opus 4.5. This is also the core reason why this model’s running speed is about three times faster than Opus 4, while the API call cost is only one-third of the latter.
The entire AI industry’s development direction is moving away from ultra-large models with trillions of parameters. The current core issue is to enhance the utilization efficiency of existing parameter scales.
Opus 4.5’s parameter count is likely capped at around 2T. The parameter count of Opus 4/4.1 might reach about 6T (MoE architecture).

Next is the 4.5 series.
Claude Sonnet 4.5 was released first, achieving a SOTA score of 60.2 in OSWorld testing for computer operations, nearly a 50% improvement over Sonnet 4.
Claude Opus 4.5 followed, with significant enhancements in front-end development and visual capabilities, excelling in routine tasks such as deep research, PPT creation, and spreadsheet processing.

The latest 4.6 series, released in February this year, has further improved capabilities.
Anthropic stated that for complex Excel filling, web lists, and other computer operation tasks, Sonnet 4.6 is approaching human levels.
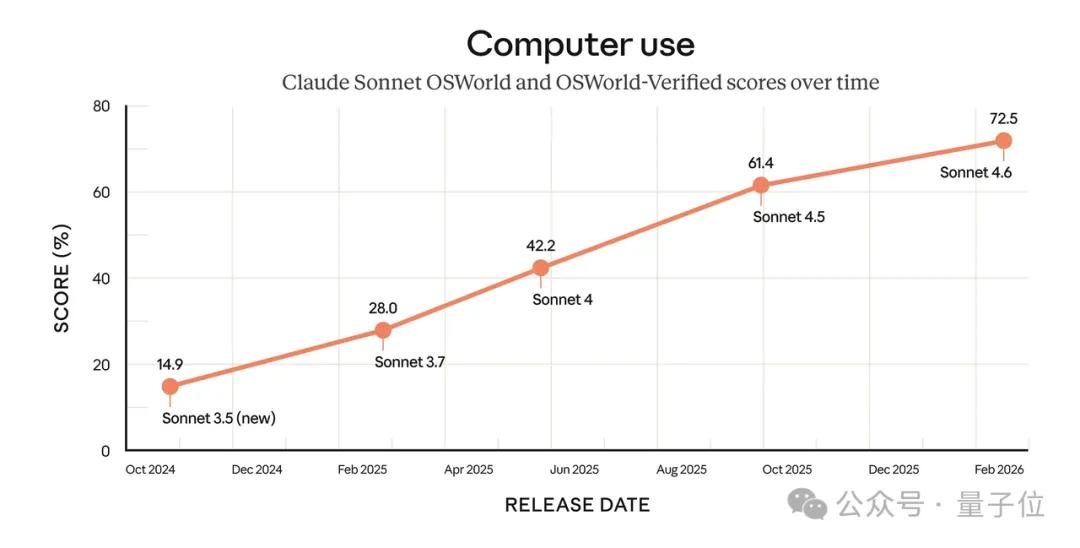
Opus 4.6 outperformed GPT-5.2 by 144 Elo on GDPval-AA, a performance metric assessing knowledge work tasks in finance, law, and other fields; it continues to lead in programming evaluations, achieving the highest score in the Agent programming assessment Terminal-Bench 2.0 and outperforming all other leading models in the “final human exam.”
As technology iterates deeper, underlying technologies and model architectures continue to innovate, making it increasingly difficult to estimate model parameter counts.
Recently, a technical reverse engineering analysis published on Substack estimated the activated parameter counts of Claude Opus 4.5 and 4.6 through Token throughput data on Google Vertex and Amazon Bedrock.
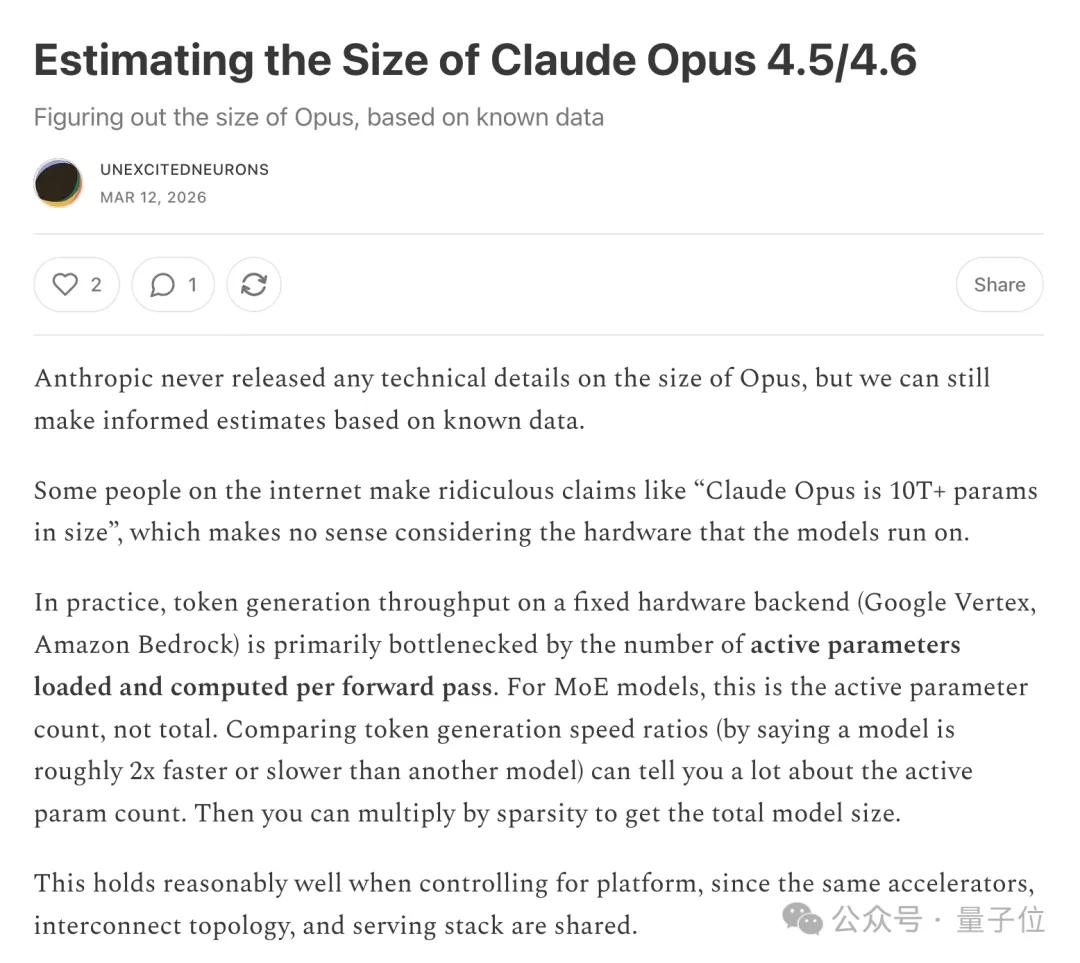
The author, signed as unexcitedneurons, used three open-source MoE models as calibration benchmarks, estimating that the effective memory bandwidth on the Vertex platform is around 4.0–4.5TB/s, leading to the conclusion that:
The activated parameter count for Opus 4.6 is approximately 93–105B under FP8 precision.
Assuming the model employs a configuration of FP8 precision dense layers + FP4 precision mixed expert layers, the activated parameter count for Opus 4.6 is around 127–154B.
Considering different expert sparsity schemes, the author ultimately believes that Opus 4.5 is not the rumored 10T+ scale, but a much smaller model distilled from Claude Opus 4/4.1, with a parameter count likely between 1.5T-2T.
This is also supported by the API pricing, where Claude Opus 4.1’s input/output pricing is $15/$75 per million tokens, while Claude Opus 4.5/4.6’s current pricing is only $5/$25 per million tokens, dropping directly to one-third of the original.
The author also mentioned that Claude Opus 4/4.1’s parameter count is likely around 5T-6T.
In addition to the released models, a few days ago, the Anthropic team accidentally leaked an unreleased model due to permission configuration errors.
The model Claude Mythos (internal code name Capybara).
The leaked document repeatedly described Mythos as a model that represents a qualitative leap, significantly outperforming Claude Opus 4.6 in software coding, academic reasoning, and cybersecurity tests.
Claude Mythos is said to be the most powerful AI model developed by the company to date.

Rumors suggest the model’s parameters reach 10T.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.