OpenAI’s Codex: Simplifying SQL Queries with Lifelong Memory
Why do data teams often find themselves in the same predicament? The answer is not merely a lack of computational power, but rather too many tables, too many definitions, and scattered experiences.
For instance, the term “active users” might have entirely different definitions across various tables. Even if the correct table is chosen, writing hundreds of lines of SQL to obtain results can lead to failure with just one incorrect join condition.
Internally, OpenAI has taken a more radical approach: it has allowed a Codex-driven data agent to take over the entire process of “finding tables, understanding tables, writing SQL, and validating results”. This is achieved through a six-layer contextual architecture that enriches data semantics, integrates organizational knowledge, and retains experiential memory, enabling engineers to ask questions instead of performing manual tasks.

Data Queries No Longer Require Manual Table Lookups
“We have a large number of structurally similar tables, and I spend a lot of time trying to understand the differences between them and which one to use,” lamented an OpenAI engineer, expressing a common frustration among data workers.
OpenAI’s internal data platform consists of 600PB of data spread across 70,000 datasets. Imagine when an OpenAI engineer needs to analyze ChatGPT user growth, facing dozens of similar user tables, each claiming to record “user activity”, but with different definitions.
Choosing the wrong table can mean days of effort wasted, and worse, making critical decisions based on incorrect data.
Even if the right table is chosen, generating correct results can be challenging. The following diagram illustrates a SQL statement with over 180 lines, resembling an insurmountable mountain—complex table joins and aggregation operations mean that any minor error could invalidate the entire analysis.

Now, with the Codex-driven intelligent agent capable of autonomous learning, engineers no longer need to write hundreds of lines of SQL queries; they can simply ask questions to find the needed information from the data ocean, such as comparing the number of active users at two different time points.
The Six-Layer “Data Brain” Architecture
While many tools can convert natural language into SQL statements, the core innovation of OpenAI’s internal data agent lies in its multi-layer contextual architecture.
The foundational layer consists of basic metadata, including table structures and column types, providing the skeleton for the data graph.
The next layer involves manual annotations, crafted by domain experts, capturing intent, semantics, business implications, and known considerations that cannot be easily inferred from patterns or historical queries. This layer serves as foundational training for the intelligent agent regarding each table’s information.
Following this, Codex enhancement derives code-level definitions of tables, allowing the agent to understand the actual content of the data more deeply. This layer provides crucial information about value uniqueness, data update frequency, and data ranges, enabling the agent to grasp the differences in construction and updates across tables.
The next layer is the institutional knowledge layer, where the agent can access Slack, Google Docs, and Notion to gather key company background information, such as product launches, reliability incidents, internal codenames, and definitions of key metrics and calculation logic.
With background information obtained from external texts, the agent avoids common sense errors. For example, when a user asks, “Why did the connector usage drop significantly in December?” the agent does not simply report the drop in numbers; instead, it identifies that this is primarily a measurement/logging issue, rather than a genuine collapse in usage, related to changes in data collection due to the ChatGPT 5.1 release.
The most critical fifth layer, learning evolution, grants the agent a lasting memory. When it receives corrections from users or discovers subtle differences in data issues, it can retain these experiences for future use. Memory can also be manually created and edited by users, applicable globally or uniquely to individual users.

The topmost layer, runtime context, allows the agent to directly check and query tables through real-time queries to the data warehouse when existing context or information is lacking. It can also communicate with other data platform systems (metadata services, Airflow, Spark) to obtain broader data context.
Dynamic Switching Between Offline Retrieval and Online Queries
How does this six-layer system work together? It can be divided into offline and online steps.
Every morning, the agent systematically scans the actual usage and calling trajectories of thousands of data tables from the previous day, absorbing the annotations and insights left by data experts, and calls Codex to interpret the logic deep within the code, deriving richer business semantics behind the tables. All these scattered “knowledge fragments” are fused into a unified, standardized “knowledge graph”.
Subsequently, through OpenAI’s embedding model, this is transformed and compressed into groups of vector embeddings, stored in a high-speed retrieval database. Thus, a readily available “data memory palace” for the AI agent is created.
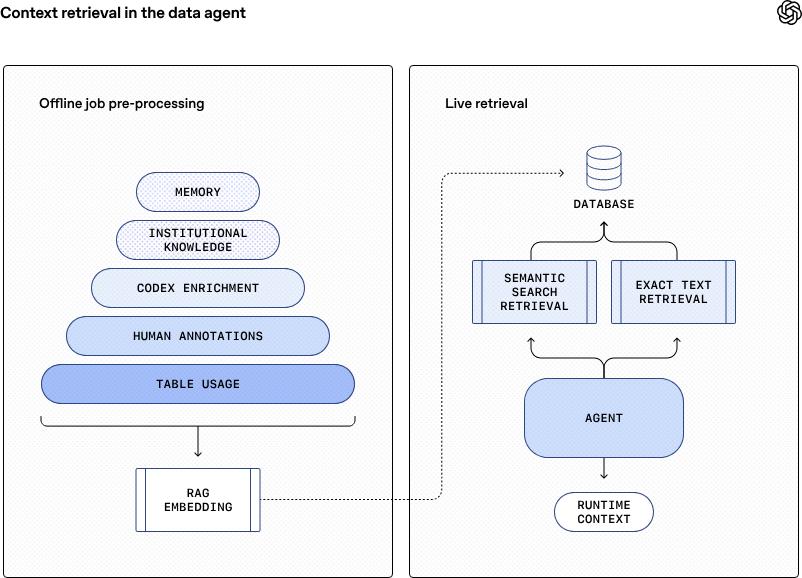
When a user’s question arrives, the agent no longer needs to dive into the vast ocean of metadata like a human analyst for time-consuming manual retrieval. Instead, it uses retrieval-augmented generation technology to precisely locate and extract the most relevant data tables for the current question. This process is fast, scalable, and has very low latency.
For requests that require the latest data, the agent simultaneously initiates a real-time query channel, directly querying the data warehouse, achieving both the immediacy of runtime context and deep integration with offline knowledge. Thus, a complex business question can be transformed into clear insights available in seconds through the collaboration of offline memory’s “lightning retrieval” and real-time data’s “precise guidance”.
From Static Tool to Dynamic Teammate
What is most astonishing about this intelligent agent is not its technical complexity, but how it integrates into daily workflows, becoming a true “teammate”. Unlike traditional “question-and-answer” tools, the data analysis agent used internally at OpenAI is designed to be a “teammate with whom one can reason”. It is conversational, always online, capable of handling quick answers as well as iterative exploration.
Imagine a scenario where a product manager’s question is vague or incomplete; the agent proactively asks clarifying questions. If there is no response, it applies reasonable default values to advance the work. For example, if a user asks about business growth without specifying a date range, it might assume the last seven or thirty days. This allows the agent to maintain a dialogue while collaborating with users to achieve more accurate results.
To prevent the ever-evolving agent from going off track during the learning process, the OpenAI team employs the Evals API to provide a strict overseer for the agent.
The Evals API is paired with manually written, gold-standard query statements for each important question, continuously monitoring and scoring the agent’s performance.
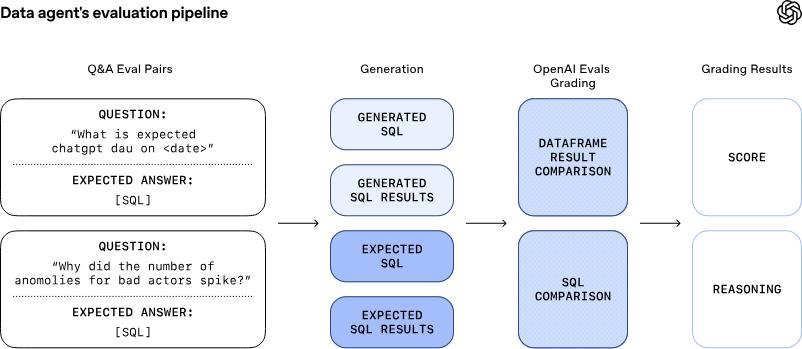
These evaluations check not only the correctness of SQL syntax but also compare the accuracy of result data. When the agent “misbehaves”, the system immediately raises an alarm, ensuring that issues are identified and resolved before impacting users.
Regarding data security, the agent stipulates that users can only query tables they have permission to access. When access rights are missing, it will flag this or revert to alternative datasets that the user is authorized to use.
To ensure transparency in the data analysis process, the agent summarizes assumptions and execution steps next to each answer to expose its reasoning process. When a query is executed, it directly links to the underlying results, allowing users to inspect the raw data and verify each step of the analysis.
How to Build a Data Analysis Intelligent Agent
OpenAI’s data analysis agent is not open-source, but if you want to build a similar agent, OpenAI’s engineers have shared some pitfalls they encountered.

Initially, the agent had access to the complete dataset, but this quickly led to confusion among overlapping data tables. To reduce ambiguity and improve reliability, developers had to restrict the tables the agent could access, thereby enhancing query reliability.
Another pitfall arose from the highly standardized system prompts provided by developers. While many questions share similar analytical shapes, the variations in details can be significant enough that rigid instructions can backfire. Focusing on the actual effects in real-world usage, allowing the agent rather than system-level prompts to determine how to achieve results, can make the agent more robust and yield better outcomes.
The most critical insight is realizing that the true meaning of data lies in the code rather than in expert annotations of data tables. Query history more accurately describes the shape and usage of tables, capturing assumptions and business intents that may never surface in SQL or metadata. By using Codex to crawl the codebase, the agent can understand how datasets are actually constructed and better infer what each table truly contains. This approach can answer questions like “What is in this table?” and “When can I use it?” more accurately than merely retrieving information from the data warehouse.
As enterprise data environments become increasingly complex, tools like OpenAI’s data agent may become standard configurations for future enterprise data analysis, driving the entire industry towards a more efficient and intelligent data-driven decision-making paradigm.
The goal of these agents is not to replace data analysts but to enhance their capabilities, freeing them from tedious query writing and debugging to focus on higher-level definitions of metrics, hypothesis validation, and data-driven decision-making.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.